One of the strengths of Microsoft’s cloud services is the deep and broad list of technical certifications that the services have achieved. These include various common standards, such as SOC I and II, and SSAE. Additionally, Microsoft meets various country-specific government standards, such as FedRAMP.
But before we go any further, it’s important to make a distinction between a “certification” and an “attestation”, because they sometimes get used interchangeably when referring to Office 365 compliance.
- Certifications are industry standards, such as ISO and SOC that are audited by a 3rd party. Microsoft is required to operate their datacenters and services according to those audited standards.
- Attestations, on the other hand, are more like 3rd party guidance, or opinions, related to specific regulations. They are reference documents created by a 3rd party that say, “Yes, the necessary controls exist in Office 365 so that you can configure your tenant to meet a given regulation.” For example, it could be HIPAA for medical and health customers, FERPA for education or FINRA for the financial industry. These attestations often provide implementation guidance, but the important point here is that the responsibility is on the customer to configure the controls in the tenant to meet the regulation. What the attestation does is confirm that the necessary controls exist in Office 365 that will allow the customer to meet that regulation.
The point of these certifications and attestations is not simply to be able to tick a checkbox on an RFP. Rather, these certifications and attestations form a foundation of trust that helps assure customers that their data, identities and privacy is being handled in a responsible way, according to a set of standards defined outside of Microsoft.
There are numerous resources a customer or partner can go to and get information about specific compliance requirements, but sometimes it can be hard to track down exactly what you’re looking for – simply because there is SO MUCH information and it’s categorized and stored in different locations.
Take for example, the SEC 17a-4 letters of attestation, which are often referred to as the FINRA attestation letters. To be clear, SEC 17a-4 is the regulation, whereas FINRA is actually the agency that enforces the regulation. (Yes, the SEC is also an enforcement agency, but let’s not muddy the waters.) These letters may be required by a customer to confirm that Office 365 meets certain regulations of the Financial Industry Regulatory Agency (FINRA) in the United States.
Since neither the customer nor the SEC have direct access to the Office 365 cloud environment, Microsoft bridges the gap through these letters of attestation to the SEC on behalf of the requesting customer.
These letters affirm, among other things, that the Office 365 service – and specifically the Immutable Storage for Azure Blobs that are the underpinnings of the Office 365 storage services – can be leveraged by the customer to preserve their data on storage that is non-rewriteable and non-erasable.
The next question is – where can a customer get that letter? Let’s talk for a moment about the various resource locations available for a customer to review to find the information they might require. (You can also skip straight to the end to get the answer about FINRA, but you’ll miss some interesting stuff.)
Trust Center
The Trust Center Resources are located at https://www.microsoft.com/en-us/trustcenter/resources
Here, you can use the drop-down selections to find articles, blogs, whitepapers, e-books, videos, case studies and other resources related to Microsoft’s compliance to different types of regulatory standards.
For example, in the screenshot below, I’ve narrowed my search down to any type of resource related to the financial industry in North America related to compliance in Office 365. The result is a single document, named IRS 1075 backgrounder.

That’s probably interesting in a different scenario, but it’s not a FINRA attestation letter, so it won’t help me in this instance.
Let’s dig some more…
Office 365 Security and Compliance Center
The next place I might look is the Office 365 Security and Compliance Center. I can get to this location in my Office 365 tenant (whether it’s a paid or a demo tenant) by going to my Admin portal, then to Admin centers, and then Security & Compliance.
Under the Service assurance section, I click on Compliance Reports.

From here, I have the ability to sort my reports according to the type of reporting I’m interested in, such as FedRAMP (for US federal government customers) and GRC (which simply means Governance, Risk and Compliance) and others.
For your reference, the same documents are available in the Trust Center here: https://servicetrust.microsoft.com/ViewPage/MSComplianceGuide
In looking through these documents, there is plenty to see, but nothing that specifically references FINRA.
Let’s look at the next blade – Trust Documents.
The default section that opens is a list of FAQs and Whitepapers, but the second section on the page is Risk Management Reports. This includes results of penetration testing and other security assessments against the cloud services, but again, no attestation letters.

The last section to click on is Compliance Manager.

The Compliance Manager tool can be accessed at any time by going to https://servicetrust.microsoft.com/ComplianceManager and logging in with your Office 365 credentials.
In Compliance Manager, you can track your organization’s level of compliance against a given regulation, such as GDPR, FedRAMP or HIPAA. I won’t go into a lot of detail about Compliance Manager here, but the basic idea is that you define the service you are interested in evaluating and the certification you’re interested in, as seen in the screenshot below.

As an example, let’s select HIPAA.
What I see now is a gauge that shows how far along my organization is in implementing all the controls related to HIPAA. Some of these controls are managed by Microsoft (such as those related to datacenter security) and others are managed by the customer (such as the decision to encrypt data).

First, I see the actual control ID, title and a description of the control, as it is defined in the HIPAA documentation. This allows me to get a quick overview of the regulation itself.
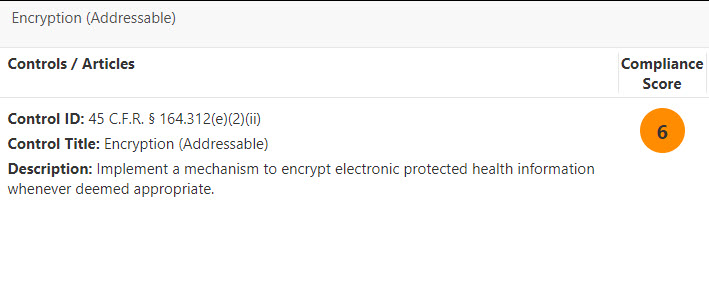
You can also see information about how you could meet the requirements for this control using Microsoft products. The screenshot below shows how Azure Information Protection and Customer Managed Keys in Office 365 could help you meet the requirement for this HIPAA control.

Next, I see a list of related controls, so that, if there are areas of overlap, I don’t necessarily need to spend a lot of time and effort planning how to implement this control. For example, in the screenshot below, if my organization has already configured the controls for ISO 27018:2014: C.10.1.1, then I can simply verify that this would also meet the HIPAA control listed in the screenshot above.
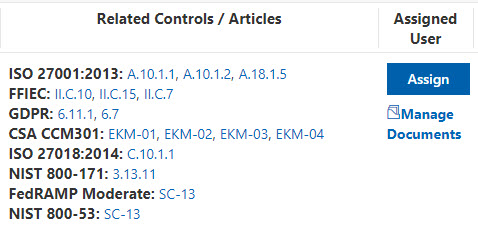
I can then use the last section to provide my supporting documentation and the date of my validation testing, along with the test results.

Compliance Manager is a powerful tool for tracking your adherence to certain regulations, but it’s still not a FINRA attestation letter.
FINRA Attestation Letter Process
The actual process for requesting a FINRA attestation letter is not very complicated at all. Go back to your main Office 365 Admin portal page and open a New service request under the Support section.

You can choose to submit a “New service request by email”, ensuring that “FINRA attestation letter” is noted at the beginning of your documentation.
The support engineer who gets the ticket will be directed to pass this along to an escalation team.
Based upon the information exchanged with the customer, the escalation team will engage CELA (Microsoft’s legal group) and they will get the attestation letter generated and executed. The final letter will look somewhat similar to this, but the highlighted areas will have the actual customer name and address.

Note that this process carries a 10-day SLA.
When the support ticket has been opened the support engineer will provide the information shown below, and then they will work with the customer to collect specific tenant-level information that ensures the accuracy of the prepared document.
Microsoft’s position, confirmed by is that Office 365 provides administrators with configuration capabilities within Exchange Online Archiving to help customers achieve compliance with the data immutability and data storage requirements of SEC Rule 17a-4.
The Azure external review confirms the ability for customers to achieve compliance with the data immutability and data storage requirements of SEC Rule 17a-4.
Microsoft actively seeks to help our customers achieve compliance with the many and varied regulatory requirements found in domestic and international jurisdictions. That said, it is important to note that while Microsoft will do all we can to assist, Microsoft itself is a not a regulated entity and does not directly comply with the SEC 17a-4 regulation.
Financial services firms are the regulated entities and as such remain responsible for direct compliance with the applicable rules when using Microsoft technologies. Due to the many variances within customer environments, financial services firms themselves need to ensure all appropriate steps have been taken to meet the regulatory requirements, including using Microsoft’s online services appropriately and training employees to do the same.
Microsoft has published the blog, Office 365 SEC 17a-4 , which offers customer-ready information along with the capability to download our whitepaper.
The SEC 17a-4 requires the regulated entity to secure a secondary resource to provide the archived data to the SEC upon request, should the regulated entity not be able or willing to provide the data to the SEC directly. Microsoft will provide data to the SEC under the terms of the regulation for Office 365 customers who remain actively licensed for the service. Data for customers who exit the service will only be retained per the current data retention policies. Microsoft will attest to meeting SEC requests for data by providing customers with the required Letter of Undertaking, addressed to the SEC and referencing the regulated entity. This letter is described within the regulation, under section 17a-4(f)(3)(vii).
The SEC 17a-4 also requires the regulated entity to attest to the immutability, quality, formatting and indexing of the archived data. This requirement is referred to as Electronic Storage Medium (ESM) Representation under section 17a-4(f)(2)(i). Microsoft will attest to the ESM capability by providing customers with the required Letter of Attestation, Electronic Storage Media Services, addressed to the SEC and referencing the regulated entity.
Hopefully, this information helps you as you work to meet FINRA compliance requirements in your Office 365 tenant.
UPDATE: On January 28, 2019, Microsoft published an article describing how Exchange Online and the Security and Compliance Center can be used to comply with SEC Rule 17a-4.
The article includes a link to the Cohasset assessment, which, it is important to note, also contains information related to Skype for Business Online. The reason for this is that Skype for Business and Microsoft Teams store data in Exchange for the purposes of eDiscovery and data retention/archival.
I encourage you to read this article as well!
Use Exchange Online and the Security & Compliance Center to comply with SEC Rule 17a-4